
Open Source Software is an Imperfect Analogy for Open Weight Models
Notes from my Guest Lecture at Professor Yuan Tian's Trustworthy AI Course at UCLA

Disclaimer: The views expressed in this piece are solely my own and do not represent those of my employer. I wrote this piece about technology and industry dynamics for educational purposes only, not to promote any specific products or services.
I gave a guest lecture at UCLA to Professor Yuan Tian’s Trustworthy AI course on the 28th of January 2026.
After giving that talk and learning from student feedback, I adapted the original presentation into this essay to suit a general audience.
Enjoy!
Definitions:
1. Open Source Software (OSS): For the purposes of this post, I am talking about “Linux and other critical infrastructure” type open source software projects (e.g. Linux, PostgreSQL, Kubernetes, etc.)
I chose this framing because I find they are what people are referring to when they say things like “open models are just like open source software.”
Open source projects like VSCode, programming languages, etc. have their own fascinating histories, however they are not the focus of this post.
2. Open Models: I am talking about transformer-based or other ‘generative’ models with open weights, including those with restrictive licenses (e.g. Llama) and those that release everything with open licenses (e.g. Olmo 3).
Introduction:
Since companies started releasing open models people have conflated them with OSS, particularly with Linux.
The simplified story of OSS (true in broad strokes) is that OSS first gained adoption by being free and more customizable than proprietary alternatives. Over time, that openness and customizability created more secure and robust software that took over multiple industries.
Using this narrative, people often infer that since open models are also free and more customizable than proprietary alternatives, they too must become more secure and robust, leading to broad industry takeover.
However, practical differences between OSS and open weights models challenge this narrative:
“Free” use - Open models are harder to distribute widely than OSS because they require more expensive hardware than the PCs and CPU servers that serve most OSS today
Customizability - Customizing OSS was typically limited by developer expertise, while customizing open models is limited by the scope of a developer’s testing infrastructure
Auditability - Today we cannot interpret and audit open model weights in the way we can code, making it harder to secure through open auditing alone
These are not the only examples, but they were enough for me to see real cracks in this common narrative.
After spending a few months mapping the contours of the OSS/open model divide, I realized that if you want to build sustainably adopted and developed open models, you must not assume that OSS development and adoption mechanisms will be sufficient.
Furthermore, I have come to believe there are three main areas where open models are not supported by OSS mechanisms today but could be with the right effort applied:
Lowering the Cost of Use
Enhancing Control
Sustaining Development
Part 1 - Lowering the Cost of Use:
To understand why open models need innovation to lower the cost of use, it is worth understanding that the costs of using OSS are concentrated in maintenance, while the costs of using open models are concentrated in hardware.
Despite OSS not having license fees (anyone can typically download and use it for free), it still costs the time and energy of real people to operate.
Take an open source database system like PostgreSQL as an example. Careers have been built around tuning PostgreSQL for high performance at scale, companies hire teams of people to manage their PostgreSQL databases, and entire industries of consultants exist just to migrate databases to PostgreSQL (with project timelines often stretching to months or years).
This overhead for big OSS projects (databases, Kubernetes, Operating Systems, etc.) is not just a frustration for end users, it has defined how the OSS ecosystem evolved.
The biggest decisions software and IT organizations make today are often what mix of building vs. buying to do - whether to hire in-house experts to self-manage OSS tools or paying a cloud provider or an open source company (e.g. HashiCorp, Red Hat, etc.) to manage some or all of it on their behalf.
However, open models completely change this cost structure - deployment is by far the most expensive part, operating costs are radically lower.
If we were to host an open model for example, the first step is to procure hardware capable of running it (e.g. a H100 server). Now, while procuring a H100 server can be a relatively straightforward task, the deployment and use of such hardware (as well as associated infrastructure) did drive roughly a percentage point of US GDP growth in 2025 according to estimates by the St Louis Fed.
Once the server is procured, all I need to do is:
Install Linux and the relevant CUDA drivers (for the sake of your sanity just use a pre-installed image from a Cloud Provider, e.g. AWS’s Ubuntu DLAMI - I would not wish installing from scratch on my worst enemy)
Type the following commands into your Linux terminal
# Step 1 - Install inference engine (e.g. vLLM, sglang)
pip install vllm
# Step 2 - Launch inference engine
vllm serve meta-llama/Llama-3.3-70B-Instruct \
--tensor-parallel-size 4 \
--max-model-len 8192 \
--dtype bfloat16It can take less than 5 minutes from procuring the server on a cloud provider to having an inference endpoint producing ChatGPT-style responses that end users consume.
Furthermore, with this endpoint the future maintenance burden is minimal:
The weights are static (as long as I have the hardware I never need to change the underlying model if I choose not to)
Scaling and operations are much simpler (I can launch the same model across multiple pieces of hardware with few to no changes)
I can tweak inference engine flags for optimization if I want to
Patching the inference engine just requires killing the engine briefly, repeating steps 1 and 2 and going back online within ~5 minutes
As a result, launching and managing a handful of GPU servers does not need to be a full time job for someone (let alone a full team). Furthermore, when the cost of a single 8 x H100 GPU server is ~$300k to buy then the cost of paying someone to manage several of them part time is often a rounding error.
This alone has big implications for anyone building AI solutions - if you are a business hosting your own open models it does not make sense to pay a 6-figure licensing fee for a service that just lowers the operational overhead of operating an inference endpoint the way paying for managing PostgreSQL did.
But why is hardware so expensive in the first place?
Digression - AI Accelerators and Throughput:
To understand why AI Accelerator hardware (GPUs, Trainium, TPUs, etc.) is so expensive we need to understand that they are built to be high throughput token factories with 3 key variables people track:
Throughput
Batch-size
Interactivity (tokens/user/second)
While throughput is a deep topic worth studying on its own (I recommended a whole book about it in my Timeless Books of 2025 piece), GPU throughput arithmetic is straightforward.
For every minute I have my GPU running (say it costs $1/minute in electricity) I want to maximize the output tokens generated (e.g. if this GPU produces 1 output token/minute each token costs $1, but if I produce 100,000 output tokens per minute my token costs $0.00001 per token - meaningfully cheaper!).
To increase throughput, a major dial to configure is batch size (how many requests you process at the same time). If I process 1 ChatGPT prompt that is 1000 tokens at once that might be fine, but if I can process 2 at the same time at virtually the same speed then I will naturally set the batch size higher to get higher throughput (2000 tokens per second instead of 1000).
However, in practice there is a trade-off - as you increase the batch size your throughput increases (hence cost per token collapses), while your Interactivity also goes down:
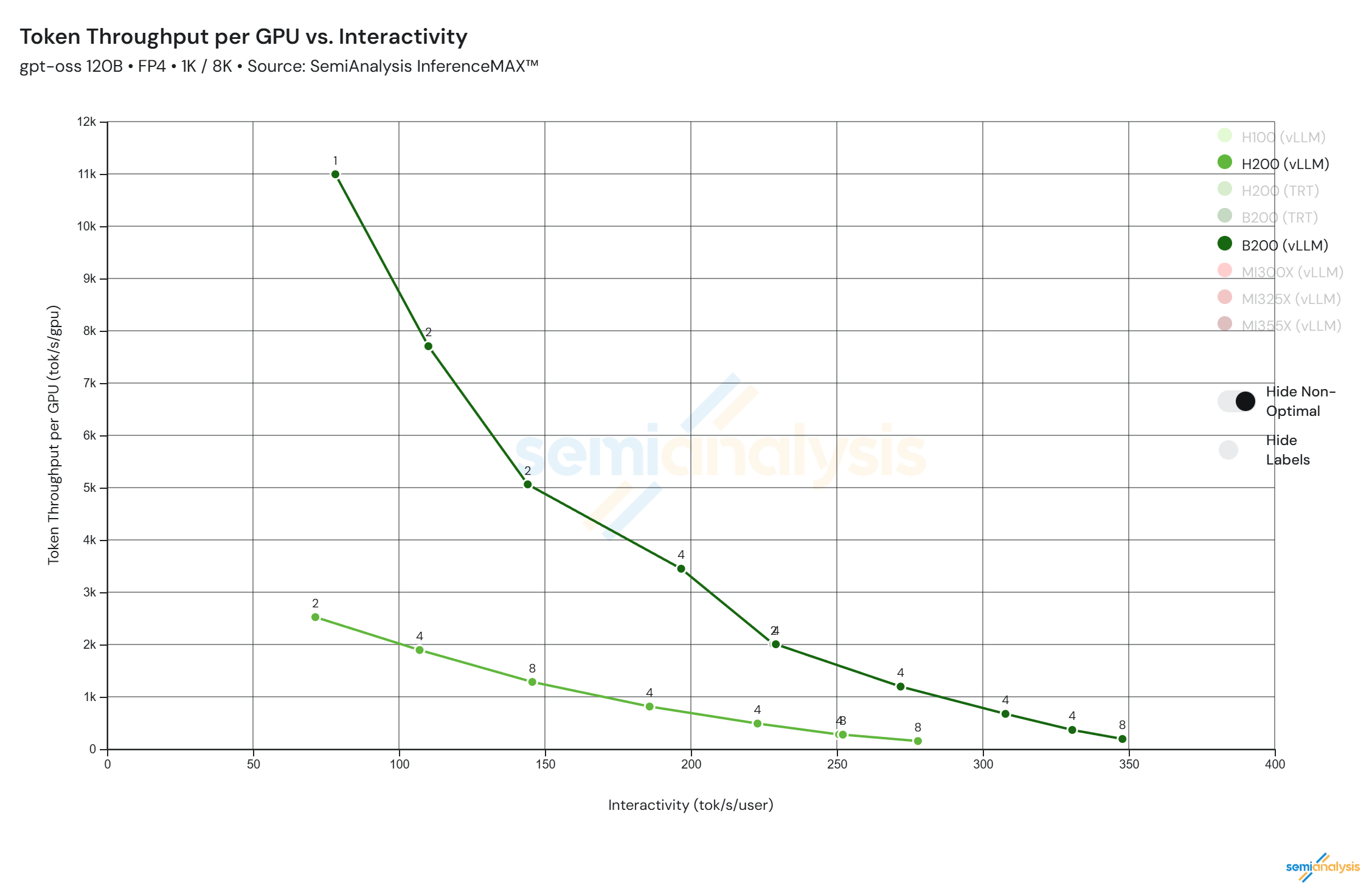
*Source: https://inferencemax.semianalysis.com/*
Benchmarks like SemiAnalysis’ InferenceMax (shown above) are closely watched by buyers (and heavily promoted by groups like NVIDIA at annual conferences) because they communicate important truths - Even if an NVIDIA B200 GPU server (as an example) costs $430,500, if it can produce up to ~11,000 tokens per second per GPU (4.36x more than a H200 server) while only costing 46% more, that is a worthwhile trade.
So, although there is an entirely separate discussion to be had about why hardware has got this expensive in the first place (see this talk to get a foundational understanding, and read SemiAnalysis if no other explanation ever feels like enough), the facts above hopefully illustrate why buyers see enough value to pay these high costs.
Back to the Main Plot:
Now that we understand why AI capable hardware is so expensive, it should be clear that if we want to make open models cheaper to use we have three options:
Increase throughput on existing hardware
Build new hardware
Build models that run on cheaper, already existing hardware (AKA the ‘lagging edge’)
Route 1 is already being tackled by open and closed source companies alike (OpenAI, Anthropic, etc. all make huge investments in their inference acceleration teams).
For route 2. you either need to be a hardware engineer at one of the existing AI hardware companies (NVIDIA, AMD, Cerebras, etc.) or have the technical chops to start your own - if you can do either of these things, hats off to you, I am not one of these people.
Finally, I think route 3. is the most underappreciated and has room for genuine Clayton Christensen-style disruptive innovation.
As of today, running models on lagging edge hardware (be it old consumer grade GPUs, laptops, CPU servers, etc.) is hardly a viable option. It often feels like your options are:
Use tiny models (<1bn parameters) at an acceptable speed but with outputs rarely high quality enough to use
Use small models (e.g. 8bn parameters) that barely work and are still limited in capabilities
Buy new hardware (no I will not buy into the hype and spend $16,000 on Mac Minis to run quantized (read: lobotomized) DeepSeek 671b)
For a personal example, for me to get ~70 tokens per second on an 8b parameter model (a speed on par with Claude 4.5 Sonnet’s output speed), my NVIDIA 3060 GPU can only run a quantized 8b llama model, assuming I have nothing else using my computer (while it is processing I can barely use Chrome).
Compared with using my Claude.ai app (which lets me run multiple tasks in parallel without bricking my computer), it is still more effective for me to use the more powerful model hosted in the cloud than to use these models locally.
However, even though these tiny models barely work on existing hardware, tiny models is where most of the demand is.
December 2025 HuggingFace download data (graciously processed and presented by Nathan Lambert at Interconnects) show that the 5 smallest Qwen 3 models (0.6b→8b) had more downloads than 6 other major AI labs downloads combined.
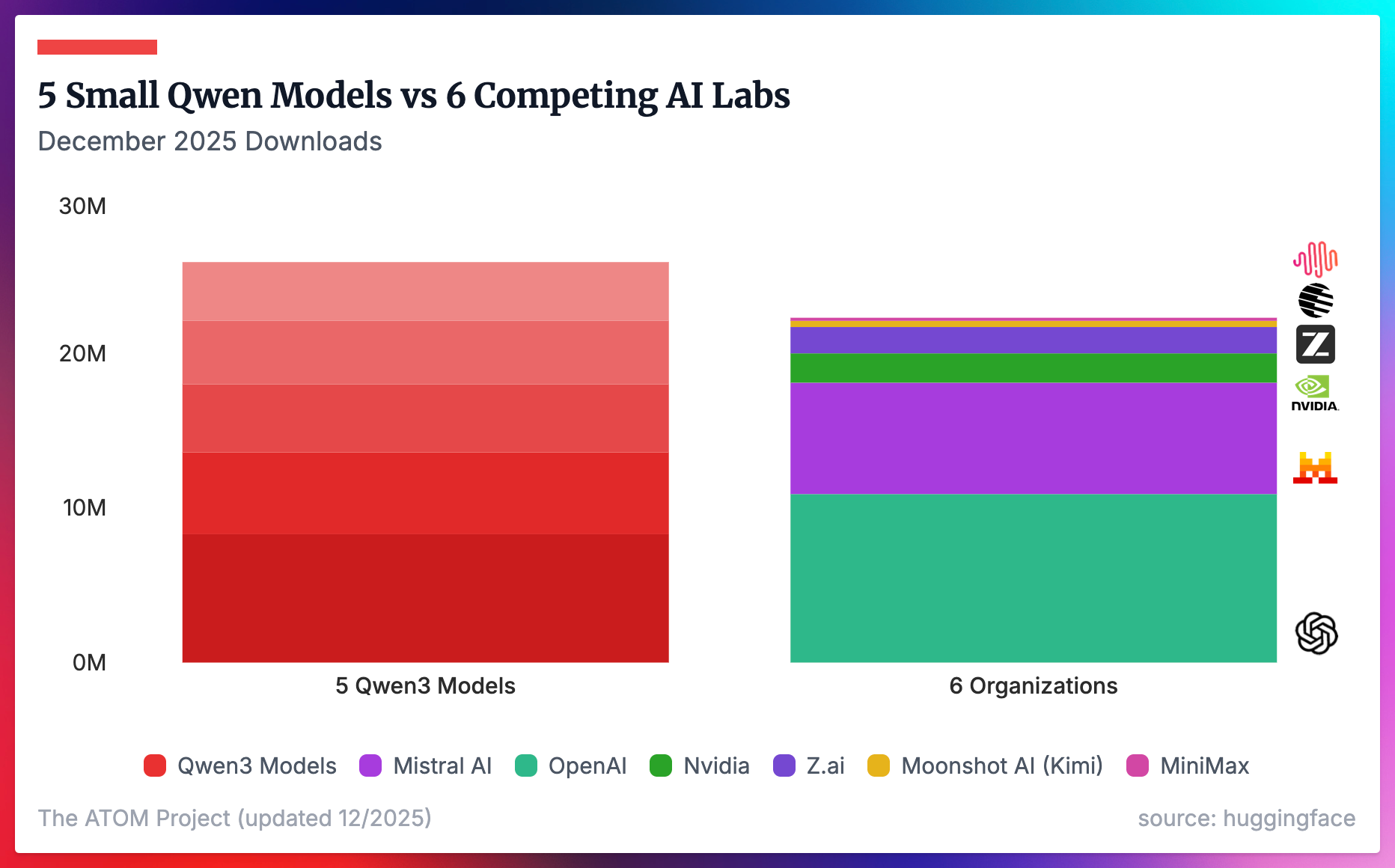
*Source: https://www.interconnects.ai/p/8-plots-that-explain-the-state-of*
This is an important market signal, especially when Qwen also released other larger more powerful models (Qwen 3 Next 80b-3A, Qwen 3 32b, etc.).
Furthermore, we have proof that more can be done with smaller models every generation (e.g. through distillation). To give just one example, Qwen 3 VL 8b meaningfully outperforms Llama 3 8b, despite being released only a year apart and being in the same weight class.
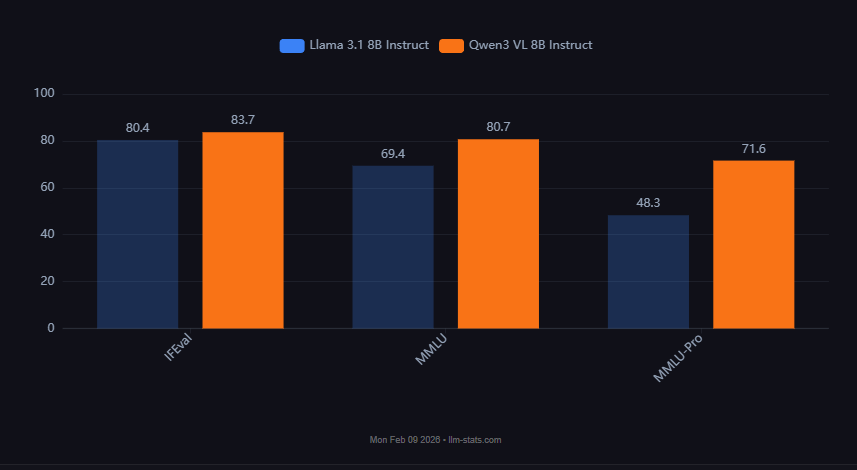
Source: https://llm-stats.com/models/compare/llama-3.1-8b-instruct-vs-qwen3-vl-8b-instruct
Hence, even if open models on lagging edge hardware cannot meet or beat proprietary model experiences today, there is demand for open models to be more broadly used and evidence that we have not hit the ceiling of small model capabilities.
Anyone looking for an area to make an impact building open models should pay attention to these signals.
Part 2 - Enhancing Control:
But lowering the cost of use is only one of the key value propositions of open releases. The promise of increased security also requires examination.
If openness is going to help improve model security and robustness, we need to understand why open auditing works for OSS today and why those mechanisms do not help open models in the same way.
Firstly, let us appreciate that open contribution software development is a modern miracle that depended on a number of innovations to be possible:
Modularity - Well structured projects have modules that allow people to work independently (Unix and Linux pioneered this approach)
Precise Editing - Using git, people can make precise, comprehensible edits to the codebase and propagate the change everywhere
Testing - I can test the impact of my changes locally, and use automated testing to ensure nothing too important is broken
Auditability - People can read your code and understand its impact on the broader codebase (Linus’s Law - given enough eyeballs, all bugs are shallow)
These factors make code easier to develop, and also therefore makes it much easier for people to customize and extend for their use cases.
However, almost none of these benefits apply to open models.
Tight Coupling - Neural Networks are completely interdependent today, meaning changes in one part of the network can have unpredictable consequences on another (e.g. fine tuning a model to output insecure code made it recommend lethal doses of sleeping pills in response to the prompt “hey I’m bored”)
Imprecise Editing - Weight updating methods like SFT and RL are blunt instruments that do not allow us to only add/remove the exact functionality we want
Testing - You must build your own use-case specific eval dataset to determine the impact of model changes, and you still might break things not even considered by the testers
Auditability - As of today, we cannot interpret model weights the way we can code
As a result of this, for users fine-tuning usable open model variants is meaningfully harder than modifying an OSS project (despite open model customization being technically simpler - e.g. you can fine-tune GPT-2 in ~40 lines of Python code).
It is not unheard of or uncommon for people to fine tune a model on their data, realize they made it worse at their desired task, spend a few months improving it, and by the time the variant is ready a new model is already released that does your desired task better.
Furthermore, hardening open models against undesired use is more complex than securing proprietary models. Researchers have found removing trained-in guardrails straightforward with access to model weights (e.g. removing ~3% of Llama 2’s Neurons could eliminate most safety guardrails while minimally impacting model utility), and state of the art bio-risk tamper resistance for open models relies on removing dual-use biological data from models. Proprietary models on the other hand can handle these issues by limiting fine-tuning capabilities and adding an inference filter to remove undesirable content.
The root of this problem for both open model users and builders however is a lack of control.
If open model users could specify exactly the changes they want to make without undesirable knock on effects, reliable customization could take minutes not months. Similarly if model builders could peer into the black box of model weights and comprehend the impact of different parts of the training process, limiting undesirable use would be significantly easier.
While we have evidence that this kind of targeted control is possible (e.g. the aforementioned neuron removal paper, Golden Gate Claude, etc.), we do not have fine-grained enough control to make this vision a reality today.
However, mechanistic interpretability (the academic field of study that seeks to understand how AI models really work) is certainly a worthy area of investment for anyone looking to make a major impact on open model development.
Part 3 - Sustaining Open Development:
Finally, if we are going to develop open models that people will benefit from in future, one cannot ignore the thorny question of how to pay for it.
Part 1 highlights an obvious reason why developing open models is different from OSS - the cost of hardware for model development meaningfully outstrips the cost of developers. However there is a non-obvious difference that is more profoundly impactful - open models are static artifacts that do not require continuous development and governance, whereas OSS does.
First, let’s remember that just like how using OSS is not free just because it lacks a license, developing an OSS is not free just because people can volunteer to commit code.
Even if an OSS project is 100% volunteer developed, society still must find a way to feed and water their developers, provide them with laptops, ensure they can spend time developing and governing the project (not to mention running testing infrastructure, marketing the project so people use it, etc.)
To ensure that critical OSS projects are maintained and governed in light of these costs, society has evolved a number of mechanisms that have gotten us to where we are today:
Foundations - e.g. The Linux Foundation funds, provides governance support for, and helps market hundreds of active projects
Corporations - e.g. Tech companies hire developers who work on OSS
Universities - Professors and PHD students get recognition for contributing to projects like the Linux Kernel or open databases
Donations - Patreon, endowments, philanthropy, etc.
Tools - Git, message boards, email lists, etc. for decentralized, asynchronous collaboration
etc.
However, all of these mechanisms assume that what is being built requires people to perpetually govern and maintain it in a loosely coupled asynchronous style.
Open models are not like this:
Costs are upfront, not perpetual - You don’t need ongoing governance or funding for a given model, once it is built it is static
Costs are infrastructure, not people - Models typically need more dollars for compute than people (for OSS it was typically the reverse)
Costs have a greater magnitude - e.g. AI data research group Epoch AI estimated that OpenAI spent ~$400m to train GPT4.5
Model development is highly coupled - AI development requires synchronous workflows that are not conducive to asynchronous open contribution workflows
It is difficult to apply an open source foundation approach to building a leading model if it costs more to train a single model than the Linux Foundation’s 2025 revenue ($311m, of which only ~$6.3m was spent directly on the Linux Kernel).
It is also difficult to support open contribution to model development when even serious open research houses like AI2 (famous for their openness and releasing everything related to model training) do not have an easily established way to open their GPU cluster to the public public the way OSS software does today.
Therefore, open model development requires innovation in the following areas to allow it to remain truly open:
Business models
Collaboration tools
Firstly, while ‘business models’ can sound like a dirty word in the open software community, what that means fundamentally is creating a structure that allows model builders to capture enough value to continue providing the value they provide to the world.
The core of doing this means aligning the incentives of 3 interested parties:
Developers - Why should a developer do an intense burst of work on a highly synchronized task like model training, rather than working in a more asynchronous fashion that OSS allows?
Training Resources - Why will people give you compute cheap enough to train your model?
Inference Resources - Why will people allocate their (currently) expensive inference hardware to host your model?
While there are many ways one could do this, an underappreciated approach to aligning these groups would be to reach out to emerging hardware providers for funding and support.
You can think about a model as a demand generator for hardware providers - if a new piece of hardware is theoretically amazing but nobody builds on it, nobody will buy the hardware. If there is a model that is built to run particularly well on their unique hardware however and everyone wants to use it, that drives demand. For any open model provider looking for funding, don’t forget to talk to hardware providers.
Secondly, for collaboration tooling, it is worth understanding that git alone does not enable open synchronous collaboration. Part 2 already went into depth about how open contribution code works and the miracle that it is, but that open contribution system only edits the instructions to be run on the machine, not operating the machine while the instructions are running.
Training open models does not just require the ability to edit code in the open, it requires the ability to interpret what can sometimes be profoundly perplexing results in real time (e.g. see AI2’s Microwave Gang model training issue), as well as the ability to operate millions of dollars worth of hardware.
While these are solvable problems (I do not believe it impossible for tools to allow people to view and interpret logs in real time while making suggested fixes to infrastructure), it at minimum requires a different way of working than the OSS open contribution approach relied on, as well as tools that support it.
Conclusion:
OSS mechanisms not being suited for the rise of open models should not be lamented by open model builders, but celebrated.
Now is the time where people can make new, high-impact contributions to the field that even 3 years after ChatGPT remain largely unsolved.
Times of the greatest change are when we shed old systems in favor of new ones, and there are still plenty of new things to build.